The Privacy Latency Curve: Why We Moved Inference to the Edge
February 20, 2026 • Cloud APIs are renting intelligence. Edge models are owning it.
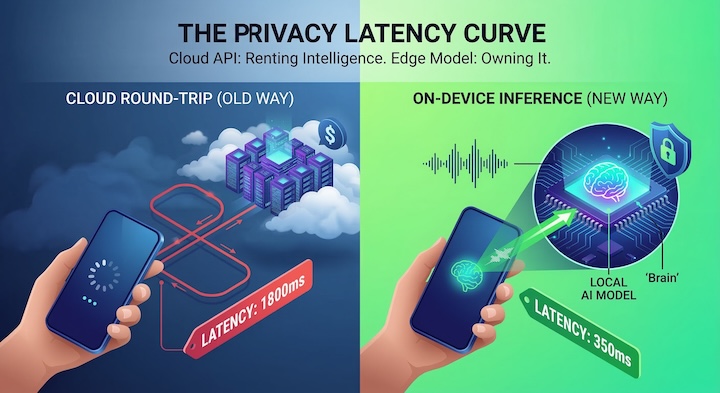
Back in 2024, the default architecture for an AI app was incredibly simplistic. You would send user input to an API like OpenAI, wait two long seconds, and then show the result on the screen. It was fine for a simple chat interface. But for Word Genie—our vocabulary tool—that sluggish "round trip" architecture turned out to be an absolute disaster for user retention.
Picture a student practicing their pronunciation. A two-second delay between speaking a word and receiving feedback completely shatters their cognitive loop. In practice, it felt less like a futuristic AI tutor and more like a frustrating phone call over a poor overseas connection. To achieve true fluidity in conversation, we had to cut the cord and eliminate the painful network latency entirely. Yet, as critical as the UX issue was, it wasn't even the main catalyst for our pivot. The real breaking point was our cloud invoice.
The Brutal Economics of the Cloud
It turns out the unit economics of cloud AI are genuinely hostile to consumer applications. Every single voice interaction triggered a billable event. As Word Genie quickly scaled to 10,000 active users, our expenses didn't just grow linearly; they compounded heavily during peak study hours because of auto-scaling overhead. Effectively, the more successful our product became, the worse our margins plunged.
- Cloud API (Solid Red Line): Exponential growth. As Daily Active Users (DAU) skyrocket, cloud providers take an ever-increasing cut due to auto-scaling overhead.
- On-Device (Blue Dashed Line): After the grueling R&D required to compress the models down, the marginal cost of a new user drops to absolute zero. The user’s phone does all the heavy lifting.
Shrinking the Brain
Moving inference to the edge essentially meant we had to shrink the AI's brain. For obvious reasons, you can’t cram a 70-billion-parameter model onto an iPhone. To solve this, we turned to 4-bit Quantization, slicing the memory footprint of smaller models like Whisper dramatically without sacrificing noticeable accuracy in speech recognition.
Word Genie now runs all voice detection locally via react-native-fast-tflite. Beyond the cost savings, it unlocked a massive narrative for our upcoming memory product, Memvoy: your voice data genuinely never leaves your device. We can confidently assure parents and users alike that "what happens on Memvoy stays entirely on Memvoy."
- Cloud: Time is wasted almost entirely on the network. Over 55% of the total wait is purely uploading audio chunks and awaiting an HTTP response (the red blocks).
- Edge: No network overhead exists. At roughly 350 milliseconds (under human conversational delay perception limits), the experience registers as completely instant.
We aren't pretending the cloud is dead. We just stopped treating it like the only hammer in our toolbox. We enforce a strict Hybrid Router model now: rapid, high-frequency evaluations (like checking if a child spoke a word correctly) happen instantly on-device for free. But when a student needs deep, semantic nuance on why their essay failed, we quietly route that query back to the cloud. It’s the only architecture that scales—giving us the zero-latency magic of native software, backed by the raw intelligence of a supercomputer only when we actually need it.